Toby Bellwood
|
Mar 19, 2026
|14 min read

Enterprise hosting isn't about ticking boxes on a compliance checklist. It's about resting easy knowing your infrastructure won't let you down at any moment. Fault-tolerant enterprise hosting should quietly and reliably do its job so that teams can focus on building meaningful products and services.
Too often, organizations are stuck choosing between paying a fortune for reliability or rolling the dice on cheaper options. That shouldn’t be the case. Fault-tolerant enterprise hosting enables both dependable performance and cost efficiency without compromise.
With amazee.io’s Cloud Basic and Cloud Pro options, you get managed, multi-tenant hosting infrastructure that delivers enterprise-grade security through logical isolation, along with predictable pricing and global availability. You don’t have to worry about managing cloud accounts or maintaining infrastructure yourself. It’s a turn-key solution that lets your team focus on building rather than babysitting servers, perfect for organisations that want reliability without the overhead.
If you need more control, our Dedicated Cloud gives you a single-tenant enterprise hosting platform on infrastructure you own and manage. Whether it’s AWS, Azure, Google Cloud, or on-premises, you decide the region, the provider, and the exact resources. This approach is ideal if your organisation has strict compliance requirements, needs full data sovereignty, or wants deep customisation. Both Cloud and Dedicated Cloud share the same fault-tolerant architecture, deployment flexibility, and support, so the difference is really about how much control you want over your environment.
Here’s the thing about fault-tolerant enterprise hosting: you can’t tack it on at the last minute and hope for the best. It either has to be built into the architecture from day one, or you’re basically crossing your fingers and hoping nothing goes wrong. That’s why we built it into our platform from the very beginning.
Self-healing infrastructure refers to a system’s ability to detect and automatically resolve failures without human intervention. On a Kubernetes-based platform like ours, this involves:
With our platform, workloads automatically spread across multiple availability zones, so if something fails, it doesn’t take the entire system down. Databases fail over in seconds, and load balancers constantly check which endpoints are healthy, dynamically rerouting traffic so your services stay online without anyone having to lift a finger.
amazee.io hosts customer sites on enterprise-scale infrastructure providers that offer multiple levels of fault tolerance. Multi-zone high availability ensures that an application remains online even if an entire data center experiences an outage. This is achieved through:
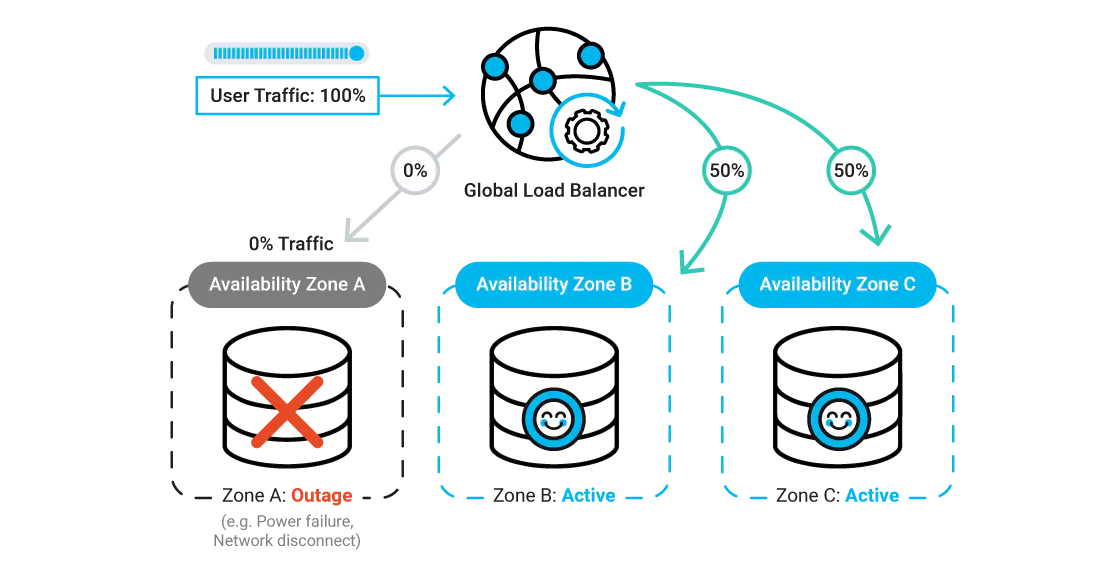
Redundancy by design: By spreading workloads across multiple availability zones, your application remains online even if an entire geographic region faces an infrastructure failure.
Every service that runs on the underlying infrastructure can also be built to provide multiple redundancy options. Our databases run on managed services spanning these same availability zones and are configured with live “reader” endpoints that can be promoted almost instantaneously to take over in the event of failure or extreme traffic. The configuration of services within the Kubernetes cluster can be optimised to run multiple concurrent instances of an application, providing load balancing and fault tolerance. amazee.io also works closely with our customers to ensure their applications are designed to maximise this functionality.
A great example is GovCMS, which powers over 350 Australian government websites. These sites deliver essential services that citizens rely on every day, and downtime can have a significant negative impact. The architecture behind GovCMS is built to prevent that scenario, keeping sites available no matter what. Kubernetes makes this possible with self-healing hosting infrastructure: containers that crash are replaced immediately, workloads are automatically moved to healthy nodes if one fails, and performance issues are caught before they escalate.
→ Dig Deeper: Modernizing Australia’s GovCMS with Fully Open Source Hosting Infrastructure. See how GovCMS modernized Australia’s whole-of-government platform using amazee.io’s open source Lagoon infrastructure. Learn how they achieved 100% uptime during 1.96 billion monthly hits and total data sovereignty.
Let’s be honest: most enterprise hosting support is frustrating at best. You hit a problem, and suddenly you’re filing tickets into a black hole. Days go by. You get bounced around. Someone reads a generic script at you while your issue barely budges. You wonder why you’re paying enterprise prices at all.
We do it differently. If something goes wrong, you will talk to a real person who actually understands your setup. These are the engineers who built the platform. They know the quirks, the edge cases, and exactly how to get things working again. And you’re not left waiting for days for a response. Our support team will work with you to solve the issue together, in real time.
We don’t just fix things when they break. We’re proactive. We spot risks before they become headaches, flag potential issues during routine reviews, and keep you in the loop every step of the way. No black boxes, no runbooks read word-for-word. Just engineers who care about your problem as much as you do and will stick with it until it’s actually solved. Support with us doesn’t feel like a service desk; it feels like having your own team in your corner.
Enterprise deployments rarely follow a neat, predictable pattern. Every organisation has its own workflows, release cycles, and compliance requirements, which means a one-size-fits-all approach just doesn’t cut it. That’s why we built our platform to give you the flexibility to deploy the way your team actually works.
With amazee.io, you can run blue-green deployments, canary releases, or rolling updates with custom health checks. You can set up environment-specific configurations, tailor your build processes, and design workflows that match your real-world needs. Different projects can follow completely different strategies, and yet everything sits on the same consistent, fault-tolerant platform foundation.
To implement a blue-green deployment, you maintain two identical production environments. The "Blue" version runs your current live traffic, while the "Green" version hosts the new release. Once testing is complete on Green, traffic is rerouted at the router or load balancer level to the new version. This strategy ensures:
A canary release is a deployment strategy that rolls out a new version of an application to a small subset of users before making it available to the entire infrastructure. Key benefits include:
A rolling update replaces old instances of an application with new ones incrementally. In a Kubernetes-based platform like amazee.io, this process is governed by custom health checks to ensure stability:
We also support a wide range of frameworks and languages, including Drupal, Node.js, Python, Go, React, and more, so your team can use the technologies that fit the job. You get full control over TLS certificates, network policies, and access controls to meet compliance requirements and maintain authority over where your data lives.
Even if your site has been built and deployed safely, and your application is running on the latest and greatest infrastructure, you will still be judged by your users on your site's performance. The critical final piece of the puzzle is ensuring that content delivery can be optimized for end users and protected during peak traffic events. This usually entails provisioning and configuring a CDN (content delivery network) and a WAF (web application firewall). amazee.io has deep experience with a number of CDN and WAF providers, and our expert team is ready to assist you with all the steps needed to provide the safety, security, and speed that your users expect
Even the most bulletproof systems eventually hit a bump in the road. The difference between a minor hiccup and a full-blown incident is preparation. That means reliable backups, clear visibility, and engineers who know your environment and are ready to act.
Our platform takes care of the technical side first. Automatic backups cover databases, persistent volumes, and configuration state, and we regularly test restores to ensure those backups work when you need them. Logs provide thirty days of detailed insight into the incident, and audit trails track every deployment, configuration change, and user action so you always know the full story. Monitoring and alerting catch issues early, often before they become emergencies.
→ Related Reading: Beyond Uptime: Why Fully Managed Secured Data Hosting is Your Best Defense. Learn how our fault-tolerant architecture serves as the foundation for a comprehensive security and compliance strategy.
Equally important is the human side. When something goes wrong, our engineers work with you directly until your services are back online. Rather than logging a ticket that gets stuck in a queue, you’re collaborating with people who understand your platform and care about solving the problem quickly. That combination of preparation, visibility, and partnership ensures that when incidents happen, recovery is fast, efficient, and predictable.
Enterprise hosting shouldn’t force you to choose between outdated architecture, vendor lock-in, or a trade-off between reliability and cost. Modern infrastructure, intelligent resource management, and a real partnership approach make it possible to have all three.
Organisations like Sandoz, GovCMS, and Renesas trust this approach because it works when it matters most. Your infrastructure should help your team build with confidence and focus on delivering value. That’s the standard we hold ourselves to every single day.
If you’re ready to stop compromising and start hosting on a platform built for reliability, flexibility, and real support, let’s talk. See how amazee.io can transform the way your team deploys, scales, and thrives.
👓 Unparalleled Site Uptime and Web Performance for Victoria University
👓 High Scalability Hosting for Your Enterprise Drupal Projects
👓 Push Your Code. We’ll Handle The Rest.


